|
Document : L'envol des octets |
|
|
|
Sources (CNRS le journal ° 269 novembre-décembre
2012) (Wikipédia)
![]()
1)- Une journée dans le monde numérique.
|
Sur Wikipédia
9 000 Nouveaux articles par
jour |
540 millions De SMS envoyés par jour |
145 milliards De mails échangés par
jour |
|
Sur Google
4,5 milliards De recherches lancées par jour |
Very large télescope
(VLT)
30 000 Mo De données collectées par jour |
Le grand collisionneur de hadrons (LHC)
40 000 Go De données collectées par jour |
|
Sur YouTube
104 000 heures De vidéos mises en ligne par jour |
552 millions D’utilisateurs connectés sur Facebook |
Sur Twitter
400 millions De tweets envoyés |
|
|
Une journée dans le monde
numérique |
|









|
- Tous les deux jours, nous produisons autant d’informations que nous en avons générées depuis l’aube de la civilisation jusqu’en 2003. - Chaque seconde, plus d’une heure de vidéo est mise en ligne sur YouTube, et plus de 1,5 million d’e-mails sont envoyés. - En huit ans (2000-2008), LE SLOAN DIGITAL SKY SURVEY, un grand programme d’observation astronomique, a enregistré 140 téraoctets. - Mais il ne faudra que cinq jours ŕ son successeur, le LSST (« LARGE SYNOPTIC SURVEY TELESCOPE »), auquel participent des équipes de l’IN2P3 du SNRS, pour acquérir ce volume. - Le grand collisionneur de hadrons (LHC), lui, amasse chaque année prčs de 15 pétaoctets de données, l’équivalent de plus de trois millions
de DVD. - Finalement, l’humanité produirait aujourd’hui, par an, un volume de l’ordre du zéttaoctet d’informations : presque autant d’octets qu’il
existe d’étoiles dans l’Univers.
-
La simulation de l’Univers dans le cadre du projet DEUS génčre
plus de 150 Po de données. - L’étude du climat nécessite de manipuler des masses de données colossales qui devraient atteindre le yettaoctet en 2020. |
![]()
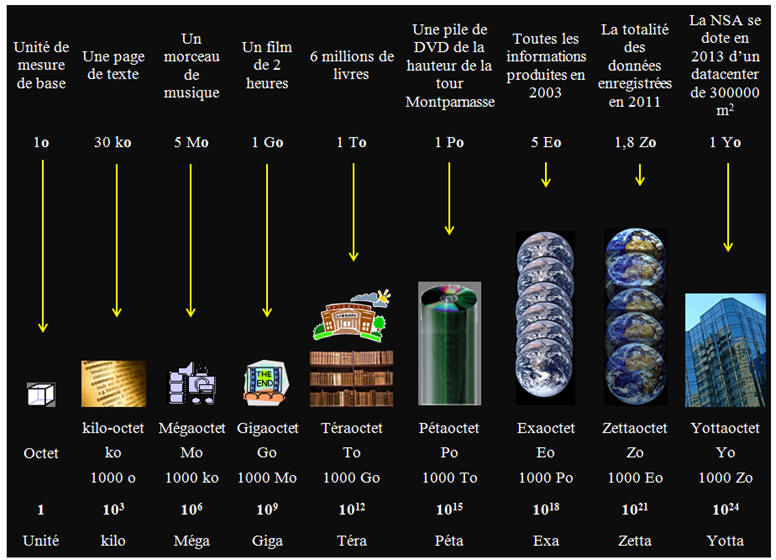
Cliquer sur l'image pour l'agrandir
|
-
Remarque : - C'est le BIPM (Bureau International des Poids et Mesures) qui est la
référence
mondiale pour les unités, et en particulier les facteurs
(kilo, Méga,
Téra,...).
-
La notation kilo (k) est officiellement : 1000 = 103.
- Cette définition est indépendante de l'unité ŕ laquelle elle s'accole: que ce soient des kilogrammes (kg), des kilomčtres (km), des kilojoules (kJ), des
kiloampčres (kA), des kilohertz (kHz) ou des
kilo-octets (ko), la définition du "kilo" ne varie pas: c'est 103.
- Cette mauvaise habitude du kilo-octet ŕ 1024 est malheureusement trčs
fortement ancrée en informatique et elle est la source de nombreuses
erreurs
d'interprétation. -
En informatique, les capacités mémoires sont en général des
multiples de puissances de 2. - Pour cette raison, les informaticiens de la premičre heure avaient l'habitude
d'utiliser les préfixes kilo, méga, etc,... comme des
puissances de 210, soit 1 024.
- Toutefois la Commission électrotechnique internationale préconise, depuis 1998, l'usage de préfixes binaires, afin d'éviter tout
malentendu, męme entre
informaticiens.
-
Il est préférable d'utiliser ces préfixes : -
kibi : 1 Ki = 210 = 1024,
-
mébi : 1 Mi = (210)2 =
10242 ≈ 1,049
× 106,
-
gibi : 1 Gi = (210)3 = 10243≈
1,074
× 109, -
etc…),
-
Et de laisser aux préfixes
SI leur sens recommandé (kilo :
1 k = 1000,
méga : 1 M = 10002,
giga : 1 G = 10003, etc…). - Les fabricants et vendeurs de supports informatiques ne s'y sont pas trompés : ils préfčrent l'usage des préfixes SI, ce qui leur
permet d'afficher des capacités apparemment plus importantes. - Ainsi un disque dur d'une capacité de 1 téraoctet = 1 To = 1000 Go correspond, avec les préfixes binaires, ŕ une capacité de 931 gibioctets,
ce qui est moins impressionnant pour le profane. |
![]() Tableau :
Tableau :
|
Nom |
Symbole |
Facteur Valeur |
|
Nom |
Symbole |
Facteur |
|
kibi |
Ki |
210 = 1,02
×
103 |
kilo |
k |
103 = 1 000 |
|
|
mébi |
Mi |
220 = 1,05
×
106 |
méga |
M |
106 = 1 000 000 |
|
|
gibi |
Gi |
230 = 1,07
×
109 |
giga |
G |
109 = 1 000 000 000 |
|
|
tébi |
Ti |
240 = 1,10
×
1012 |
téra |
T |
1012 = 1 000 000 000 000 |
|
|
pébi |
Pi |
250 = 1,13
×
1015 |
péta |
P |
1015 = 1 000 000 000 000 000 |
|
|
exbi |
Ei |
260 = 1,15
×
1018 |
exa |
E |
1018 = 1 000 000 000 000 000 000 |
|
|
zébi |
Zi |
270 = 1,18
×
1021 |
zetta |
Z |
1021 = 1 000 000 000 000 000 000 000 |
|
|
yobi |
Yi |
280 = 1,21
×
1024 |
yotta |
Y |
1024 = 1 000 000 000 000 000 000 000 000 |
3)- Les préfixes du systčme décimal :
![]() Tableau 1 : les préfixes du systčme décimal.
Tableau 1 : les préfixes du systčme décimal.
|
Facteur |
Nom |
Symbole |
|
Facteur |
Nom |
Symbole |
|
101 |
deca |
da |
10–1 |
déci |
d |
|
|
102 |
hecto |
h |
10–2 |
centi |
c |
|
|
103 |
kilo |
k |
10–3 |
milli |
m |
|
|
106 |
Méga |
M |
10–6 |
micro |
µ |
|
|
109 |
Giga |
G |
10–9 |
nano |
n |
|
|
1012 |
Téra |
T |
10–12 |
pico |
p |
|
|
1015 |
Péta |
P |
10–15 |
femto |
f |
|
|
1018 |
Exa |
E |
10–18 |
atto |
a |
|
|
1021 |
Zetta |
Z |
10–21 |
zepto |
z |
|
|
1024 |
Yotta |
Y |
10–24 |
yocto |
y |
![]() Tableau 2 : les préfixes du systčme décimal et étymologie.
Tableau 2 : les préfixes du systčme décimal et étymologie.
|
Facteur |
Nom |
Symbole |
Étymologie |
|
1024 |
Yotta |
Y |
Grec :
okto : « huit » : 10008 = 1024 |
|
1021 |
Zetta |
Z |
Latin :
septem : « sept » : 10007 = 1021 |
|
1018 |
Exa |
E |
Grec : hex : « six » :
10006 = 1018 |
|
1015 |
Péta |
P |
Grec : « cinq » :
10005 = 1015 |
|
1012 |
Téra |
T |
Grec : téras : monstre : tétra :
« cinq » : 10004 = 1012 |
|
109 |
Giga |
G |
Grec : gigas : géant |
|
106 |
Méga |
M |
Grec : mégas : grand |
|
103 |
kilo |
k |
Grec : khilioi : mille |
|
102 |
hecto |
h |
Grec : hekaton : cent |
|
101 |
deca |
da |
Grec : déka : 10 |
|
100 |
1 |
Unité |
|
|
10–1 |
déci |
d |
Latin : décimus : dixičme |
|
10–2 |
centi |
c |
Latin : centésimus : centičme |
|
10–3 |
milli |
m |
Latin : mille : milličme |
|
10–6 |
micro |
µ |
Grec : mikros : petit |
|
10–9 |
nano |
n |
Latin : nanus : nain |
|
10–12 |
pico |
p |
Italien : piccolo : petit |
|
10–15 |
femto |
f |
Danois : femten : quinze |
|
10–18 |
atto |
a |
Danois : atten : dix-huit |
|
10–21 |
zepto |
z |
Évoque 7 :
Latin : septem : « 7 » : (10–3)7 = 10–21 |
|
10–24 |
yocto |
y |
Évoque 8 :
Grec : okto : « huit » : (10–3)8 = 10–24 |
|
- Dans le domaine du calcul haute performance ou HPC (« High performance computing »), les États-Unis restent le leader incontesté. - Sur les 500 supercalculateurs les plus puissants existant sur la plančte en 2012, ils en concentrent en effet 252, soit en effet prčs de la moitié de la puissance réelle disponible qui atteint désormais 120
pétaflops (PFlops).
- Un superordinateur « pétaflopique » est capable de réaliser un million de milliards d’opérations en virgule flottante par seconde. -
Péta : 1 000 000
× 1 000 000 000 = 1015 -
1 PFlops = 1015 opérations / seconde
- La France regroupe 22 de ces supercalculateurs, pour une puissance totale de 6,4 PFlops. -
L’hexagone se classe au 6e rang mondial en termes de
puissance dédiée au calcul intensif. - Au sein du CNRS, le centre de calcul de l’IN2P3 est un acteur majeur du calcul intensif via le développement de grilles informatiques destinées aux expériences du
LHC ainsi qu’ŕ des
applications biomédicales et industrielles - Le supercalculateur Curie est capable d’effectuer jusqu’ŕ 2 millions de milliards d’opérations par seconde et de stocker
l’équivalent de 7600 ans de fichiers de musique. |
![]()
|
- Les « BIG DATA », littéralement les « grosses données », parfois appelées « données massives », est une expression anglophone utilisée pour désigner des ensembles de données qui deviennent tellement volumineux qu'ils en deviennent difficiles ŕ travailler avec des outils classiques de gestion de base de données ou de gestion de l'information. |
![]()
2)- Un enjeu économique majeur.
|
- Avec le succčs de l’économie numérique, la généralisation des appareils mobiles, le boom des réseaux sociaux, l’ouverture au public de certaines bases de données (« l’open Data ») ou encore le développement de grands programmes scientifiques internationaux, le phénomčne du « BIG
DATA » va en s’amplifiant. - Ces grandes masses de données sont devenues un tel enjeu économique, industriel et scientifique que les gouvernements et les entreprises investissent massivement dans ce domaine. - Aux États-Unis, le président OBAMA a dévoilé en mars un plan « BIG DATA » allouant 200 millions de dollars ŕ la recherche dans ce domaine (« Big Data Research and Development Initiative »). - De son côté, l’Europe a inscrit la gestion des contenus numériques dans ses priorités pour la fin du 7e
programme-cadre de recherche et de développement
technologique. -
En France, les Investissements d’avenir se sont aussi emparés du
sujet. - Un programme de 25 millions d’euros est consacré aux techniques d’exploitation des trčs grands volumes de données. |
![]()
3)- La révolution du « BIG DATA »
dans les sciences humaines et sociales.
|
-
L’čre numérique a facilité pour les chercheurs l’accčs ŕ
l’information, autrefois dispersée dans les bibliothčques. -
Les grandes masses de données ont révolutionné le travail des
spécialistes des sciences humaines et sociales. - Grâce aux bases de données en ligne, nous avons aisément accčs ŕ une somme de connaissances qu’il nous fallait trouver dans des
bibliothčques souvent dispersées. -
Les enquętes sur internet ont facilité le travail des
sociologues. |
![]()
4)- Un défi pour les scientifiques.
|
- Le « BIG DATA » constitue un défi scientifique considérable qui nécessite des travaux aussi bien en ingénierie que dans
les sciences fondamentales. - L’idée est de soutenir des projets interdisciplinaires afin d’identifier oů sont les verrous dans la gestion des grandes masses de
données scientifiques. -
Les questions qui se posent : -
Comment stocker les données et les pérenniser ? -
Comment les traiter, les analyser, les visualiser, leur donner du
sens ? -
Comment les protéger, empęcher leur usage abusif et aussi les
supprimer ? -
Analyse de Farouk
TOURMANI : - « Prenez le LSST, ce télescope, qui doit ętre mis en service en 2020, sera capable d’enregistrer des images du ciel de 3 milliards de pixels toutes les 17 secondes. Ŕ la fin du programme, les astronomes disposeront ainsi d’une base de données de 140 pétaoctets,
avec des centaines de caractéristiques pour chaque objet du ciel. » - Or, aujourd’hui, les algorithmes de fouille de données les plus efficaces mettraient des dizaines d’années pour explorer la base de
données et répondre ŕ certaines questions des chercheurs. - Les scientifiques engagés dans le programme LSST savent déjŕ que certaines de leurs interrogations les plus complexes resteront
sans réponse. - Cependant, une telle base de données constitue le champ d’application ręvé pour qui veut faire avancer la recherche fondamentale
dans le domaine du « BIG DATA ». -
Il faut contourner les obstacles rencontrés dans la gestion des
grandes masses de données : -
Il faut améliorer les technologies de stockage et de calcul, -
Il faut aussi inventer de nouvelles maničres de manipuler les
données. -
Personne n’échappe au phénomčne du « BIG DATA » et aux
problčmes qu’il engendre. -
Désormais, le volume d’informations produites dans le monde
numérique double tous les deux ans et le rythme s’accélčre. -
Les données numériques représentent une matičre premičre ŕ forte
valeur ajoutée. |
![]()
|
- Aujourd’hui, si les chiffres correspondant aux informations numériques disponibles ont de quoi donner le tournis, ils soulčvent aussi une question essentielle, celle de la difficile analyse de ces masses de données considérables et en perpétuelle expansion. - Un moteur de recherche comme Google, dans lequel nous formulons une requęte, se contente de proposer une liste de milliers de documents correspondant ŕ cette demande. Il laisse ensuite ŕ l’usager le fastidieux travail d’investigation destiné ŕ identifier la réponse la
plus pertinente ŕ sa requęte. - Face ŕ l’accroissement vertigineux des documents disponibles sur le Net, de tels modčles risquent d’ętre rapidement submergés par le flot
d’informations ŕ gérer. -
Il faut faire évoluer le réseau actuel vers un Web de données. |
![]()
2)- La visualisation, source
d’interprétation.
|
- La profusion de données dont disposent les chercheurs n’est pas toujours un avantage. En effet, plus les données disponibles sont nombreuses, plus il devient compliqué de les interpréter. - Au laboratoire bordelais de recherche informatique (LABRI) David Auber et son équipe s’efforcent d’améliorer la lisibilité de ces masses de données grâce ŕ des méthodes de visualisation analytiques. - « La démarche consiste ŕ appliquer des outils mathématiques de type algorithmes sur ces données brutes pour faire ressortir les
informations les plus pertinentes. » - Les données provenant des cours de la Bourse, de systčmes de communications, des processus chimiques du métabolisme cellulaire, de réseaux géographiques ou sociaux peuvent ainsi ętre traduites sous forme
de métaphores visuelles. - Ces représentations doivent permettre aux chercheurs d’analyser de maničre rapide et efficace la structure de ces masses d’informations. - Si l’évolution exponentielle des capacités de calcul numérique a permis de générer des quantités de données considérables au cours des dix derničres années, les facultés d’analyse de notre cerveau n’ont pas
suivi la męme évolution. -
Notre mémoire ŕ court terme ne nous permet pas d’analyser
simultanément plus de sept éléments distincts. |
![]()
|
- L’évolution du réseau vers un Web de données se fonde sur l’association de métadonnées aux adresses URL qui identifient les pages
Web. - Ceci afin de casser la complexité du Web actuel, en structurant l’information sur internet de maničre ŕ pouvoir accéder de maničre plus
simple ŕ la connaissance. -
Ce Web plus performant est déjŕ en marche, c’est le
W3C. - Le World Wide Web Consortium, abrégé par le sigle W3C, est un organisme de normalisation ŕ but non lucratif, fondé en octobre 1994 chargé de promouvoir la compatibilité des technologies du World Wide Web telles que HTML, XHTML, XML, RDF, SPARQL, CSS, PNG, SVG
et SOAP. - Fonctionnant comme un consortium international, il regroupe au 26 février 2013, 383 entreprises partenaires. -
Le leitmotiv du
W3C est « un seul web partout et pour
tous ». |
![]()
|
-
Nos sociétés produisent un déluge de données et il faut bien les
stocker quelque part. - La solution la plus évidente est bien sűr de multiplier des unités de stockage, comme les disques durs qui équipent les ordinateurs ou les puces ŕ mémoire flash de nos appareils mobiles. - Mais si ce principe général est valable pour les masses de données, sa réalisation ne coule pas de sources. - Empiler (les spécialistes disent « paralléliser ») les systčmes de stockage ne suffit pas, il faut aussi optimiser la façon dont ils
travaillent ensemble. -
Cette tâche est d’autant plus épineuse sont non seulement trčs
nombreuses, mais aussi hétérogčnes et dynamiques. - De nouvelles maničres de stocker l’information ont vu le jour, notamment sous l’impulsion des géants de l’internet comme Google, qui
doit conserver la trace de milliards de pages Web. - Des solutions spécifiques sont apparues. - Elles exploitent le
parallélisme massif avec de nouveaux modčles de programmation de cette
parallélisation. |
![]()
|
-
Ce sont des centres de données oů sont installés des systčmes de
calcul et de stockage massivement parallčle. - Ces Datacenters sont implantés dans les pays du Nord, car toutes les machines doivent ętre constamment refroidies et cela coűte moins
cher de le faire sous un climat froid. - C’est dispositif que l’on désigne sous le nom de « cloud computing » : ce fameux « nuage » qui permet de louer, de maničre
temporaire ou durable, un espace de stockage et męme de temps de calcul. - C’est sur ce modčle que fonctionne le « nuage élastique de calcul » d’Amazon, service visant surtout les entreprises, ou des services plus grand public comme les Google Apps et iCloud d’Apple,
destinés aux utilisateurs d’ordinateurs, de tablettes et de téléphones. |
![]()
|
-
Le disque dur magnétique reste ŕ ce jour le principal support
employé - C’est un ensemble de plateaux de verre ou de métal qui tournent ŕ vive allure (120 tr / s le plus souvent), ŕ l’intérieur d’un boîtier
étanche. -
Chaque plateau est recouvert d’une couche magnétique oů sont
enregistrées les données. - Aujourd’hui, les disques durs du commerce stockent environ 15 gigaoctets par centimčtre carré de plateau, un chiffre qui pourrait
doubler d’ici 2016. - Parallčlement le prix des disques durs a chuté de maničre vertigineuse. En 1956, quand IBM a présenté son premier disque dur,
stocker 1 Go coűtait 8 millions d’euros. -
Aujourd’hui, cela ne coűte plus que quelques centimes d’euros. -
De fait seule la bande magnétique, dix fois moins chčre, peut
rivaliser en terme de coűt. - Mais celle-ci a un gros inconvénient, sa lenteur. On la réserve donc ŕ l’archivage de données peu fréquemment utilisées. - La mémoire flash, qui équipe le plus souvent les appareils mobiles, acquiert peu ŕ peu ses lettres de noblesse. Elle est plus rapide pour la lecture des données que le disque dur et de plus elle
voit son rapport coűt / performance baisser ŕ vue d’śil. |
![]()
-
Le cloud computing :
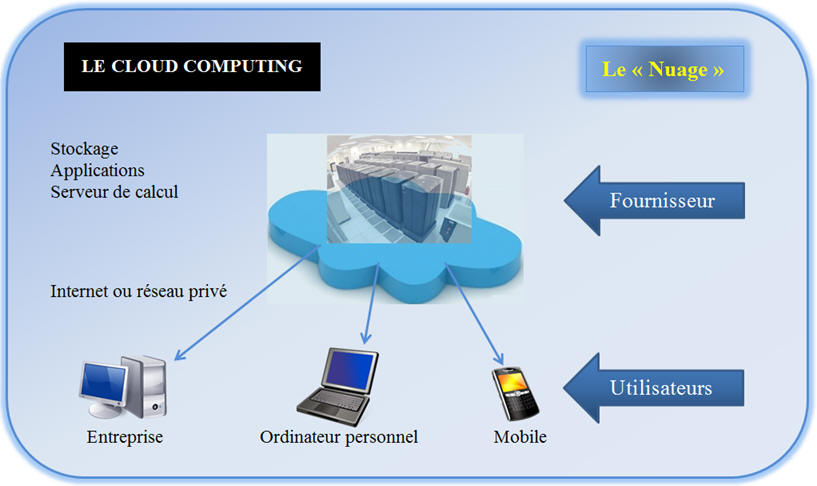
Cliquer sur l'image pour l'agrandir
|
-
Le développement des « nuages » se heurte encore ŕ beaucoup de
réticences, ceci pour des raisons de confidentialité. -
Le plus souvent, les serveurs stockent des données de maničre
lisible et les gens qui gčrent ces serveurs ont accčs aux informations
de leurs clients. - Pour résoudre ce problčme, il suffirait de chiffrer les données chez le client avant l’envoi dans le « nuage ». - Mais cela rend
plus complexe l’accčs aux données, cela augmente les temps de calcul et
donc les coűts. -
Autre point faible, les « nuages » offrent un point d’entrée
centralisé qui les rend vulnérables aux attaques des pirates
informatiques. -
Comme de nombreux sites proposent un contrôle d’accčs unique pour
tous les services, une attaque réussie peut provoquer de gros dégâts. -
Pour parer ce genre de menaces, les recherches se concentrent sur
la détection des attaques avant qu’elles surviennent et sur le
cloisonnement des données. -
En Europe, la question de la sécurité des données se pose
d’autant plus que la plupart des fournisseurs de « nuage », ŕ l’image
d’Amazon et de Google, sont sous pavillon américain. -
Ils sont soumis au
PATRIOT ACT. - Cette loi adoptée au lendemain des attentats du 11 septembre 2001, donne tout pouvoir au gouvernement fédéral pour accéder aux
données hébergées sur le serveur d’une société de droit américain, quel
que soit le pays oů ce serveur est installé. -
Un droit de regard extraterritorial qui inquičte et semble
freiner les utilisateurs européens. |
![]()
|
-
Mastodons est l’un des défis lancés par la Mission pour
l’interdisciplinarité du CNRS. -
Lancé en 2012, le projet Mastodons en rencontré un franc succčs.
-
En ŕ peine trois semaines, 37 projets ont été présentés : -
Dix projets fédérateurs, -
Cinq projets ciblés (sur la préservation des données) -
Un projet d’animation (sur la présentation des données), -
Ont été retenus. -
Leur financement s’élčve ŕ 700 000 € en 2012. -
Chaque projet de Mastodons pourrait durer 4 ans. -
Le premier colloque a eu lieu le 5 décembre 2012 ŕ Paris. |
![]()
2)- Exemple : le projet
Amadouer.
|
-
Analyse de masse de données sur l’environnement et l’urbain. - Il s’agit ici d’explorer la base de données de l’agglomération lyonnaise pour y recueillir les informations sur la pollution
environnementale et le flux de circulation automobile. -
Le traitement de ces données doit aider ŕ élaborer une nouvelle
politique des transports en centre-ville. -
Ŕ l’aide de simulations mathématiques, l’objectif est de
concevoir un modčle dans lequel la voiture n’aurait plus qu’une place
limitée. |
|
|
|
|